Semantic segmentation: ENet
- by TobiasWeis
- in Allgemein
- posted January 13, 2018
In order to be safe, reliable and fast, autonomous cars need to be able to perceive their environment and react accordingly. One of my key interests is in camera sensors and computer vision, so today I tested a semantic segmentation method that is based on Convolutional Neural Nets, in an encoder-decoder architecture.
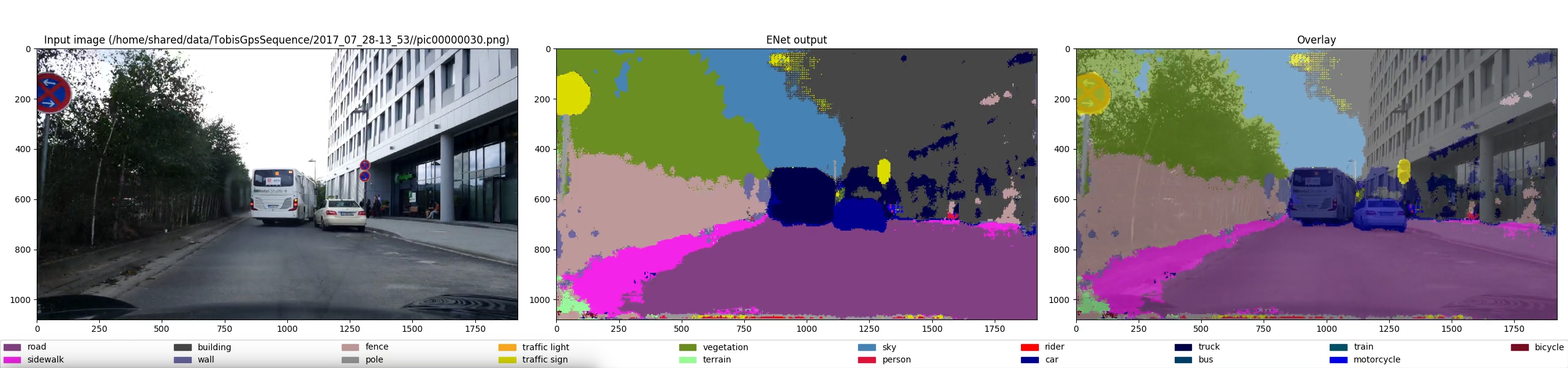
Semantic segmentation means that the system tries to explain every pixel in an input image by assigning a label to it. The system I tested is called ENet, a work by Adam Paszke, Abhishek Chaurasia, Sangpil Kim and Eugenio Culurciello, their paper can be found here: https://arxiv.org/abs/1606.02147.
A guy called Timo Sämann provides a running version using the caffe framework on github. The code looks really good, and the provided tutorial helps to run the code right away. He even provides a “shortcut”: You can just download the weights of an already trained network and only use the inference methods on your own data.
Here is a short video of the results I got when I ran the network on my own dataset (a sequence using a 1920×1080 cellphone camera at approximately 10Hz):
Although it already looks pretty good, I am not yet satisfied with these results. There still are a lot false-positives, especially for cars, and I think it will be difficult to extract definite objects from these masks in order to make actionable estimates about objects in the world.